테라폼의 Plan뿐 아니라, terraform fmt를 통해 코드 형태를 포멧팅하고 변경되는 리소스를 리뷰
또한 테라폼과 함께 동작하는 tfsec이나 terrascan 같은 보안 취약성 점검 툴 등을 활용하는 것도 좋은 방안
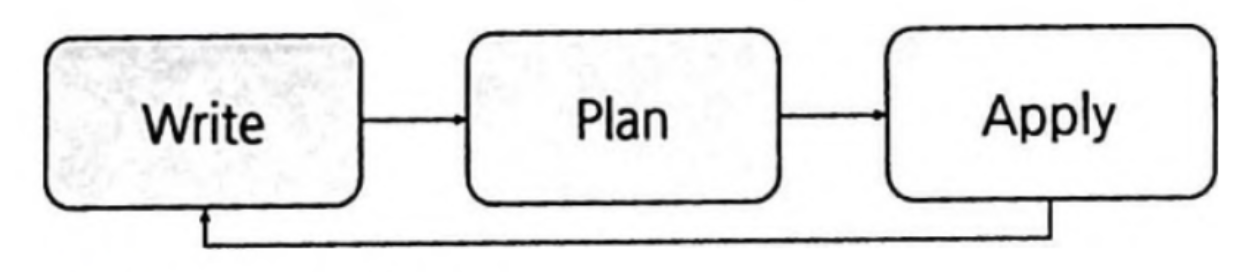
Apply : 인프라 프로비저닝
plan에선 정상이지만 실제 프로비저닝하는 단계에서 인수 값, 생성 순서, 종속성에 따라 오류가 발생 가능
성공적인 완료를 위해 Write > Plan > Apply 단계를 반복하고 성공하는 경우 코드 관리를 위해 VCS에 코드를 병합.
8.1.2 다중 작업자 워크플로
팀의 워크플로
Write
여러 작업자의 테라폼 코드가 충돌하지 않도록 형상관리 도구에 익숙해져야 한다.
작업자는 작업 전에 미리 원격 저장소의 코드를 받고(pull, fetch) git에서는 브랜치를 활용해 개별적으로 작업한다.
개인의 워크플로에서 고려한 변수화와 더불어 패스워드와 인증서 같은 민감 데이터가 포함되지 않도록 코드를 설계한다. 또한 개인 작업 환경에서만 사용되는 변수는 공유하지 않는다.
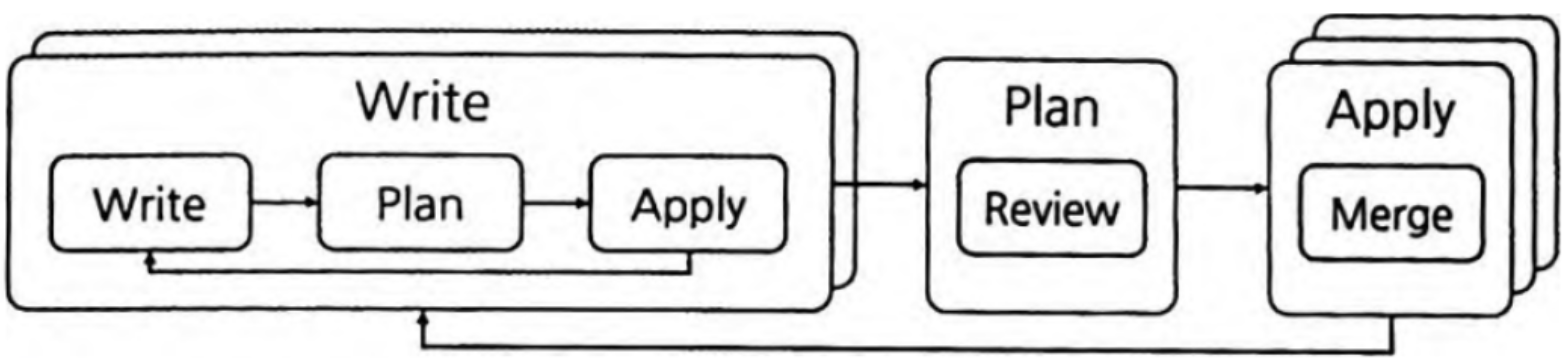
깃을 사용한다면 작업자 개인의 변수는 terraform.tfvars 에 선언하고 .gitignore에 추가해 개별적으로 테스트할 수 있는 환경을 구성할 수 있다(이거 레알 짱인듯). 이 단계에서 개별 작업자는 더 작은 단위의 개인별 워크플로(Write > Plan > Apply)를 반복해야 한다.
개별 작업 환경과 별개로 병합되는 코드가 실제 운영 중인 인프라에 즉시 반영되면 실행 후 발생할 오류 예측이 어려워 부담이 될 수 있다. 이를 보완하기 위해 프로비저닝 대상의 환경을 검증과 운영, 또는 그 이상의 환경으로 구성 가능하도록 구조화한다.이때 사용하는 방식은 디렉터리 기반 격리와 깃 기반의 브랜치 격리다.
둘 이상의 작업자는 프로비저닝 이전에 팀원 간 리뷰를 거쳐 변경된 내역을 확인하고 공통 저장소에 병합해야 한다.
리뷰 단계에서는 추가, 삭제, 수정된 내역을 관련 작업자가 검증, 질의, 배움의 단계를 거쳐 복기함으로써 코드 상태를 개선 유지하고 작업자 간에 의도를 공유한다.
코드 자체 외에도 테라폼의 Plan 결과를 풀 리퀘스트 단계에 같이 제공하면 영향을 받는 리소스와 서비스 중단에 대한 예측이 더 쉬워진다.
CI 툴과 연계하거나 Terraform Cloud/Enterprise의 VCS 통합 기능으로 자동화할 수 있다.
Apply
코드가 최종 병합되면 인프라 변경이 수행됨을 알리고 변경되는 대상 환경의 중요도에 따라 승인이 필요할 수 있다.
또한 변경하는 코드가 특정 기능, 버그 픽스, 최종 릴리즈를 위한 병합인가에 따라 이 단계에 추가로 코드 병합이 발생할 수 있다.
관리하는 단위를 나누는 기준은 조직 R&R, 서비스, 인프라 종류 등으로 구분된다.
8.1.3 다수 팀의 워크플로
R&R이 분리된 다수 팀 또는 조직의 경우 테라폼의 프로비저닝 대상은 하나이지만 관리하는 리소스가 분리된다.
단일 팀의 워크플로가 유지되고 그 결과에 대해 공유해야 하는 핵심 워크플로가 필요!
다수 팀의 워크플로
Write
대상 리소스가 하나의 모듈에서 관리되지 않고 R&R에 의해 워크스페이스가 분리된다.
서로 다른 워크스페이스에서 구성된 리소스 데이터를 권한이 다른 팀에게 공유하기 위해, 저장된 State 접근 권한을 제공하고 output을 통해 공유 대상 데이터를 노출한다.
테라폼 코드 작성 시 다른 워크스페이스에서의 변경 사항을 데이터 소스로 받아 오는 terraform_remote_state 또는 별도 KV-store를 활용하는 코드 구성이 요구된다.
또한 관리 주체가 다른 곳에서 생긴 변경 사항의 영향을 최소화하도록 리모트 데이터 소스의 기본값을 정의하거나 코드적인 보상 로직을 구현하는 작업이 필요하다.
Plan
코드 기반으로 진행되는 리뷰는 반영되는 다른 팀의 인프라를 VCS상의 코드 리뷰만으로도 공유받고 영향도를 검토할 수 있다.
병합을 승인하는 단계에 영향을 받는 다른 팀의 작업자도 참여해야 한다.
Apply
프로비저닝 실행과 결과에 대한 안내가 관련 팀에 알려져야 하므로 파이프라인 구조에서 자동화하는 것을 추천한다.
실행 후의 영향도가 여러 팀이 관리하는 리소스에 전파될 수 있으므로 코드 롤백 훈련이 필요하다.
생성된 결과에 다른 워크스페이스에서 참조되는 output 값의 업데이트된 내용을 다른 팀이 확인하는 권한 관리가 필요하다
8.2 격리 구조
테라폼 수준의 격리 목표 : State를 분리
테라폼은 파일이나 하위 모듈로 구분하더라도 동작 기준은 실행하는 루트 모듈에서 코드를 통합하고 하나의 State로 관리한다.
애플리케이션 구조가 모놀리식(+아키텍처)에서 MSA로 변화하는 과정은 테라폼의 IaC 특성과도 결부된다.
모놀리식과 MSA 비교
테라폼 또한 사용하는 리소스가 적고 구조가 단순하면 모놀리식 방식으로 구성하는 것이 인프라 프로비저닝 구축 속도는 빠를 수 있다.
하지만 유지 보수, 인수인계, 운영의 관점에서는 프로비저닝 단위별로 분류하는, 마치 MSA와도 같은 분산된 설계가 매몰 비용과 기술 부채를 줄이는 데 효과적이다.
규모가 큰 워크플로를 만들기 위해서는 간단하고 조합 가능한 부분들이 모여 집합을 이루어야 한다.
이러한 집합에서 발생하는 정보는 다른 집합과 교환할 수 있지만, 각 집합은 독립적으로 실행되며 다른 집합에 영향을 받지 않는 격리된 구조가 필요하다.
초기 테라폼 적용 단계에서 단일 또는 소수의 작업자는 단일 대상에 대해 IaC를 적용하고 하나의 루트 모듈에 많은 기능을 포함시킬 가능성이 높다.
8.2.1 루트 모듈 격리(파일/디렉터리)
모놀리식 구조의 파일 디렉토리 격리 구조
단일 작업자가 테라폼으로 프로비저닝을 하는 많은 경우에 관리 편의성 및 배포 단순화를 위해 하나의 루트 디렉터리에 파일로 리소스들을 구분하거나, 디렉터리를 생성하고 하위에 구성 파일 묶음을 위치시켜 루트 모듈에서 하위 디렉터리를 모듈로 읽는 구조를 사용한다.
작업자가 관리하는 영역 또는 프로비저닝되는 리소스 묶음의 독립적인 실행을 위해 단일 루트 모듈 내의 리소스를 다수의 루트 모듈로 분리하고 각 모듈의 State를 참조하도록 격리한다.
관리적인 측면으로는 작업자들의 관리 영역을 분리시키고 깃 기준의 리모트 저장소도 접근 권한을 관리할 수 있다.
협업과 관련해 작업자별로 특정 루트 모듈을 선정해 구성 작업을 진행해 코드 충돌을 최소화하는 환경을 구성하고 인수인계 과정에서 리뷰하는 영역을 최소화할 수 있다.
8.2.2 환경격리 -깃 브랜치
서비스의 테스트, 검증, 운영 배포를 위해 테라폼으로 관리하는 리소스가 환경별로 격리되어야 한다면 디렉터리 구조로 분리하는 방안을 고려할 수 있다.
디렉터리별로 각 환경을 나누는 것은 개인의 관리 편의성은 높지만, 환경의 아키텍처를 고정시키고 코드 수준의 승인 체계를 만들기 위해서는 최종 형상에 대한 환경별 브랜치를 구성하기를 권장한다.
디렉터리 구조 만으로는 환경에 따라 사용자를 격리할 수 없다. 이때 깃의 브랜치 기능을 활용하면 환경 별로 구별된 작업과 협업이 가능하다.
깃 플로 예시
브랜치 전략
main : 운영 코드가 관리되며 이곳에는 직접적으로 구성 변경을 수행하지 않음
QA : 검증 대상 인프라를 구성하는 코드로, 메인 브랜치와 같이 직접적인 구성 변경을 수행하지 않음
DEV : QA 전 단계로 메인 코드 구성과 기능 브랜치의 병합을 담당
feature : 새로운 리소스를 추가하고 구현하며 여러 개가 될 수 있음
관리의 편의성을 고려해 Hot-fix와 Release 브랜치를 추가할 수도 있지만 인프라의 특성상 개발, 검증, 운영으로 나눈다.
환경 간에 프로비저닝이 되는 리소스를 갖추고 있다면 운영을 위한 프로비저닝 환경을 안정적으로 유지할 수 있다는 장점이 있다.
디렉터리 구조로 관리하는 환경별 디렉터리 구성 방식에서는 개발할 때 작성한 구성을 다시 복사해 검증 또는 운영에 반영하므로 환경별로 구성이 다른 상황이 발생할 여지가 높고, 모든 디렉터리에 접근 가능할 경우 검증과 운영을 위한 구성을 직접 수정하는 일이 발생할 가능성이 높다.
따라서 작업자가 다수의 환경을 동시에 관리한다면 디렉터리로 구분하더라도 각 디렉터리마다 동일한 깃 저장소의 브랜치별 리모트 구성을 하는 것이 바람직하다.
디렉토리 격리에 깃 브랜치 연결
이 방식은 동일한 브랜치를 변경해가면 작업해 발생하는 실수를 줄일 수 있고, 각 브랜치가 연결되어 있으므로 단일 작업자가 다수의 환경을 관리하는 이점과 각 환경별로 리소스 구성이 동일하게 유지되는 장점이 있다.
terraform init && terraform plan
terraform apply -auto-approve
# State List 및 생성된 Password 확인
terraform state list
terraform state show random_password.mypw
# State에 저장된 result를 확인해보자! -> 어떻게 관리해야할까요?
ls *.tfstate
cat terraform.tfstate | jq
cat terraform.tfstate | jq | grep result
YLGmKyb3jOuI8sEf
# (참고) sensitive value 내용은 테라폼 콘솔에서 보일까요?
echo "random_password.mypw" | terraform console
echo "random_password.mypw.result" | terraform console
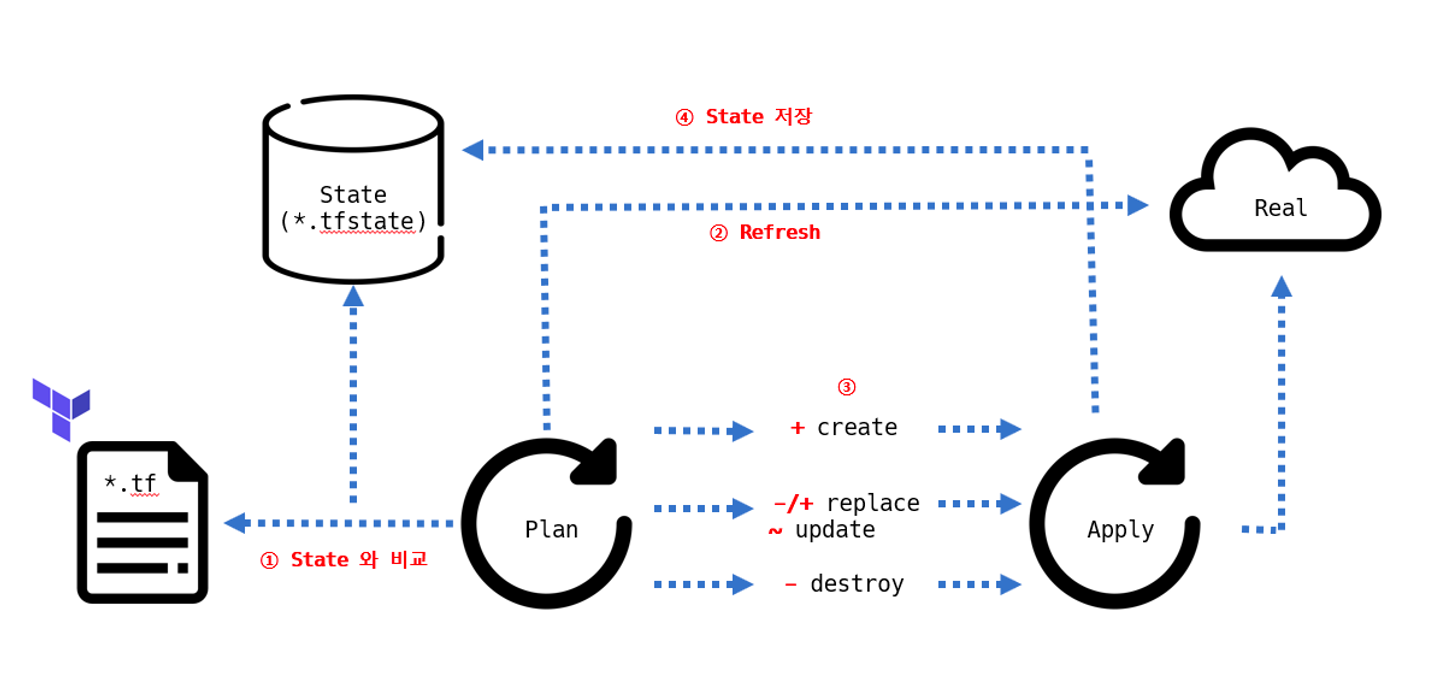
테라폼에서는 JSON 형태로 작성된 State를 통해 속성과 인수를 읽고 확인할 수 있다. 테라폼에서는 type과 name으로 고유한 리소스를 분류하며, 해당 리소스의 속성과 인수를 구성과 비교해 대상 리소스를 생성, 수정, 삭제한다.
State는 테라폼만을 위한 API로 정의할 수도 있다. Plan을 실행하면 암묵적으로 refresh 동작을 수행하면서 리소스 생성의 대상(클라우드 등)과 State를 기준으로 비교하는 과정을 거친다. 이 작업은 프로비저닝 대상의 응답 속도와 기존 작성된 State의 리소스 양에 따라 속도 차이가 발생한다. 대량의 리소스를 관리해야 하는 경우 Plan 명령에서 -refresh=false 플래그를 사용해 State를 기준으로 실행 계획을 생성하고, 이를 실행에 활용해 대상 환경과의 동기화 과정을 생략할 수 있다.
# 실행 계획 생성 시 저장되어 있는 State와 실제 형상을 비교하는 기본 실행
time terraform plan
# 실행 계획 생성 시 실제 형상과 비교하지 않고 실행 계획을 생성하는 -refresh=false 옵션
time terraform plan -refresh=false
5.2 State 동기화
테라폼 구성과 State 흐름 : Plan 과 Apply 중 각 리소스에 발생할 수 있는 네 가지 사항, 아래 실행 계획 출력 기호와 의미기호 의미
+
Create
-
Destroy
-/+
Replace
~
Updated in-place
Replace 동작은 기본값을 삭제 후 생성하지만 lifecycle의 create_before_destroy 옵션을 통해 생성 후 삭제 설정 가능
유형 별 실습 + 문제상황 추가 : 테라폼 구성에 추가된 리소스와 State에 따라 어떤 동작이 발생하는지 다음 표로 살펴본다유형 구성 리소스 정의 State 구성 데이터 실제 리소스 기본 예상 동작
1
있음
리소스 생성
2
있음
있음
리소스 생성
3
있음
있음
있음
동작 없음
4
있음
있음
리소스 삭제
5
있음
동작 없음
6
있음
있음
유형1 : 신규 리소스 정의 → Apply ⇒ 리소스 생성(처음부터 Terraform 코드로 작업)
locals {
name = "mytest"
}
resource "aws_iam_user" "myiamuser1" {
name = "${local.name}1"
}
resource "aws_iam_user" "myiamuser2" {
name = "${local.name}2"
}
#########
terraform init && terraform apply -auto-approve
terraform state list
terraform state show aws_iam_user.myiamuser1
ls *.tfstate
cat terraform.tfstate | jq
terraform apply -auto-approve
ls *.tfstate
# iam 사용자 리스트 확인
aws iam list-users | jq
유형2 : 실제 리소스 수동 제거 → Apply ⇒ 리소스 생성
# 실제 리소스 수동 제거
aws iam delete-user --user-name mytest1
aws iam delete-user --user-name mytest2
aws iam list-users | jq
# 아래 명령어 실행 결과 차이는? (refresh 유무)
# 실제 리소스는 제거되었으나 -refrest=false로 인해 변경사항 없으므로 인식
terraform plan
terraform plan -refresh=false
cat terraform.tfstate | jq .serial
#
terraform apply -auto-approve
terraform state list
cat terraform.tfstate | jq .serial
# iam 사용자 리스트 확인
aws iam list-users | jq
유형3 : Apply → Apply - 코드, State, 형상 모두 일치한 경우 ⇒ 변경사항 없음
locals {
name = "mytest"
}
resource "aws_iam_user" "myiamuser1" {
name = "${local.name}1"
}
#####################
# 코드 변경으로 인해 user2 삭제
terraform apply -auto-approve
terraform state list
terraform state show aws_iam_user.myiamuser1
ls *.tfstate
cat terraform.tfstate | jq
# iam 사용자 리스트 확인
aws iam list-users | jq
유형5 : 리소스만 있으며 코드, State는 없는 경우 → Import 또는 신규코드 작성
유형6 : 실수로 tfstate 파일 삭제 → plan/apply ← 책에는 없는 내용
# 실수로 tfstate 파일 삭제
rm -rf terraform.tfstate*
# 아래 두 명령 결과 차이는?
# Local에 State 파일이 없으므로 두 명령 모두 새로운 리소스 추가(add) 계획
terraform plan
terraform plan -refresh=false
# apply할 경우 어떤 결과 발생?
# 이미 리소스가 있으므로 Error 발생: EntityAlreadyExists: User with name mytest1 already exists.
terraform apply -auto-approve
terraform state list
cat terraform.tfstate | jq
# iam 사용자 리스트 확인
aws iam list-users | jq
# 다음 실습을 위해 iam user 삭제
aws iam delete-user --user-name mytest1
CE와 Cloud/Enterprise에서 제공되는 Workspace의 기능을 비교해보자!Component Local Terraform Terraform Cloud/Enterprise
Terraform configuration
On disk
In linked version control repository, or periodically uploaded via API/CLI
Variable values
As .tfvars files, as CLI arguments, or in shell environment
In workspace
State
On disk or in remote backend
In workspace
Credentials and secrets
In shell environment or entered at prompts
In workspace, stored as sensitive variables(via Vault)
테라폼 구성 파일은 동일하지만 작업자는 서로 다른 State를 갖는 실제 대상을 프로비저닝할 수 있다.
워크스페이스는 기본 default로 정의된다. 로컬 작업 환경의 워크스페이스 관리를 위한 CLI 명령어로 workspace가 있다.
terraform workspace list
* default
실습
resource "aws_instance" "mysrv1" {
ami = "ami-0ea4d4b8dc1e46212"
instance_type = "t2.micro"
tags = {
Name = "t101-week4"
}
}
실행
# [분할/터미널1] 모니터링
export AWS_PAGER=""
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------" ; sleep 1; done
# [분할/터미널2] 배포
terraform init && terraform apply -auto-approve
terraform state list
#
cat terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
cat terraform.tfstate | jq -r '.resources[0].instances[0].attributes.private_ip'
# terraform.tfstate에 private 담긴 내용은?
cat terraform.tfstate | jq -r '.resources[0].instances[0].private' | base64 -d | jq
# 워크스페이스 확인
terraform workspace list
# graph 확인
terraform graph > graph.dot
신규 워크스페이스 생성 및 확인
# 새 작업 공간 workspace 생성 : mywork1
terraform workspace new mywork1
terraform workspace show
# 서브 디렉터리 확인 -> 향후 저장되는 State는 여기에!
tree terraform.tfstate.d
terraform.tfstate.d
└── mywork1
# plan 시 어떤 결과 내용이 출력되나요?
terraform plan
# apply 해보자!
terraform apply -auto-approve
# 워크스페이스 확인
terraform workspace list
# State 확인
cat terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
cat terraform.tfstate.d/mywork1/terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
# graph 확인
terraform graph > graph.dot
# (실습생략)새 작업 공간 workspace 생성 : mywork2
terraform workspace new mywork2
# 서브 디렉터리 확인
tree terraform.tfstate.d
...
# plan & apply
terraform plan && terraform apply -auto-approve
cat terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
cat terraform.tfstate.d/mywork1/terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
cat terraform.tfstate.d/mywork2/terraform.tfstate | jq -r '.resources[0].instances[0].attributes.public_ip'
# workspace 정보 확인
terraform workspace show
terraform workspace list
# 실습 리소스 삭제
terraform workspace select default
terraform destroy -auto-approve
terraform workspace select mywork1
terraform destroy -auto-approve
terraform workspace select mywork2
terraform destroy -auto-approve
장점
하나의 루트 모듈에서 다른 환경을 위한 리소스를 동일한 테라폼 구성으로 프로비저닝하고 관리
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_security_group" "instance" {
name = "t101sg"
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_instance" "example" {
ami = "ami-0c9c942bd7bf113a2"
instance_type = "t2.micro"
subnet_id = "subnet-0b92d8356a0cbca38"
private_ip = "172.31.0.100"
key_name = "kp-kaje" # 각자 자신의 EC2 SSH Keypair 이름 지정
vpc_security_group_ids = [aws_security_group.instance.id]
user_data = <<-EOF
#!/bin/bash
echo "Hello, T101 Study" > index.html
nohup busybox httpd -f -p 80 &
EOF
tags = {
Name = "Single-WebSrv"
}
}
resource "aws_eip" "myeip" {
#vpc = true
instance = aws_instance.example.id
associate_with_private_ip = "172.31.0.100"
}
resource "null_resource" "echomyeip" {
provisioner "remote-exec" {
connection {
host = aws_eip.myeip.public_ip
type = "ssh"
user = "ubuntu"
private_key = file("/home/kaje/kp-kaje.pem") # 각자 자신의 EC2 SSH Keypair 파일 위치 지정
#password = "qwe123"
}
inline = [
"echo ${aws_eip.myeip.public_ip}"
]
}
}
output "public_ip" {
value = aws_instance.example.public_ip
description = "The public IP of the Instance"
}
output "eip" {
value = aws_eip.myeip.public_ip
description = "The EIP of the Instance"
}
수정 실행
# 프로비저너 필요로 설치
terraform init -upgrade
# 실행 : EIP 할당 전 (임시) 유동 공인 IP 출력
terraform plan
terraform apply -auto-approve
...
null_resource.echomyeip (remote-exec): Connected!
null_resource.echomyeip (remote-exec): 13.125.25.238
...
Outputs:
eip = "13.125.25.238"
public_ip = "43.201.63.58"
#
terraform state list
terraform state show aws_eip.myeip
terraform state show aws_instance.example
terraform state show null_resource.echomyeip
# graph 확인 > graph.dot 파일 선택 후 오른쪽 상단 DOT 클릭
terraform graph > graph.dot
# 데이터소스 값 확인
echo "aws_instance.example.public_ip" | terraform console
echo "aws_eip.myeip.public_ip" | terraform console
# 출력된 EC2 퍼블릭IP로 curl 접속 확인
MYIP=$(terraform output -raw eip)
while true; do curl --connect-timeout 1 http://$MYIP/ ; echo "------------------------------"; date; sleep 1; done
삭제: `terraform destroy -auto-approve`
null_resource는 정의된 속성이 ‘id’가 전부이므로, 선언된 내부의 구성이 변경되더라도 새로운 Plan 과정에서 실행 계획에 포함되지 못한다.
따라서 사용자가 null_resource에 정의된 내용을 강제로 다시 실행하기 위한 인수로 trigger가 제공된다.
trigger는 임의의 string 형태의 map 데이터를 정의하는데, 정의된 값이 변경되면 null_resource 내부에 정의된 행위를 다시 실행한다.]
첫번째 _를 기준으로 앞은 프로바이더 이름, 뒤는 프로바이더에서 제공하는 리소스 유형 ex)local_file - local이라는 이름의 프로바이더에서 제공하는 file이라는 리소스 유형
데이터 소스 유형 선언 뒤에는 고유한 이름을 붙인다
리소스 이름과 마찬가지로 중복 될 수 없다 -> 식별자 역할
이름 뒤 데이터 소스 유형에 대한 구성 인수들은 {} 안에 선언한다
data "local_file" "abc" {
filename = "${path.module}/abc.txt"
}
데이터 소스 정의시 사용가능한 메타인수
depends_on
종속성 선언
선언 구성요소와 생성 시점에 대해 정의
count
선언된 개수에 따라 여러 리소스 생성
for_each
map 또는 set타입의 데이터 배열의 값을 기준으로 여러 리소스 생성
lifecycle
리소스의 수명 주기 관리
# 실습 확인을 위해서 abc.txt 파일 생성
echo "t101 study - 2week" > abc.txt
# -auto-approve가 있으면 yes를 묻지 않음
terraform init && terraform plan && terraform apply -auto-approve
terraform state list
# 테라폼 콘솔 : 데이터 소스 참조 확인
echo "data.local_file.abc" | terraform console
데이터 소스 속성 참조
3.6 입력 변수 Variable
Input Variable로 테라폼에서는 정의
인프라를 구성하는데 필요한 속성 값을 정의
코드 변경 없이 여러 인프라 생성 가능하게 하는데 목적
변수 선언 방식
변수는 variable로 시작되는 블록으로 구성된다.
변수 블록 뒤의 이름 값은 동일 모듈 내 모든 변수 선언에서 고유해야 하며, 이 이름으로 다른 코드 내에서 참조된다.
테라폼 예약변수 이름으로는 사용이 불가능하다.
# variable 블록 선언의 예
variable "<이름>" {
<인수> = <값>
}
variable "image_id" {
type = string
}
sensitive : 민감한 변수 값임을 알리고 테라폼의 출력문에서 값 노출을 제한 (암호 등 민감 데이터의 경우)
nullable : 변수에 값이 없어도 됨을 지정
변수 유형
기본 유형
string, number, bool, any(명시적으로 모든 유형이 허용됨을 선언)
집합 유형
list (<유형>): 인덱스 기반 집합
map (<유형>): 값 = 속성 기반 집합이며 키값 기준 정렬
set (<유형>): 값 기반 집합이며 정렬 키값 기준 정렬
object ({<인수 이름>=<유형>, …})
tuple ([<유형>, …])
list와 set : 선언하는 형태가 비슷하지만 참조 방식이 인덱스와 키로 각각 차이가 있다
map와 set : 선언된 값이 정렬되는 특징
입력 변수 사용 예시
# number
variable "number_example" {
description = "An example of a number variable in Terraform"
type = number
default = 42
}
# list
variable "list_example" {
description = "An example of a list in Terraform"
type = list
default = ["a", "b", "c"]
}
# 조건 결합1 : 모든 항목이 number인 list
variable "list_numeric_example" {
description = "An example of a numeric list in Terraform"
type = list(number)
default = [1, 2, 3]
}
# 조건 결합2 : 모든 값이 String 인 mapvariable "map_example" {
description = "An example of a map in Terraform"
type = map(string)
default = {
key1 = "value1"
key2 = "value2"
key3 = "value3"
}
}
# 구조적 유형 (Structural type)
# object나 tuple 제약 조건을 사용해서 만든 복잡 유형
variable "object_example" {
description = "An example of a structural type in Terraform"
type = object({
name = string
age = number
tags = list(string)
enabled = bool
})
default = {
name = "value1"
age = 42
tags = ["a", "b", "c"]
enabled = true
}
}
3.7 local 지역 값
variable "prefix" {
default = "hello"
}
locals {
name = "terraform"
content = "${var.prefix} ${local.name}"
my_info = {
age = 20
region = "KR"
}
my_nums = [1, 2, 3, 4, 5]
}
locals {
content = "content2" # 중복 선언되었으므로 오류가 발생한다.
}
코드 내에서 사용자가 지정한 값 또는 속성 값을 가공해 참조 가능한 local (지역 값)
외부에서 입력되지 않고, 코드 내에서만 가공되어 동작
선언된 모듈 내에서만 접근 가능 (입력변수와 차이점)
변수처럼 실행시 입력받을 수 없음
장단점
장점 : 값이나 표현식을 반복적으로 사용할 수 있는 편의 제공
단점
빈번하게 여러 곳에서 사용되는 경우 실제 값에 대한 추적이 어려움
유지 관리 부담 커짐
주의할 것
3.8 출력 output
output "instance_ip_addr" {
value = "http://${aws_instance.server.private_ip}"
}
주로 테라폼 코드의 프로비저닝 수행 후의 결과 속성 값을 확인하는 용도로 사용된다.
프로그래밍 언어에서 코드 내 요소 간에 제한된 노출을 지원하듯, 테라폼 모듈 간, 워크스페이스 간 데이터 접근 요소로도 활용 가능
자바의 getter와 비슷한 역할?
output의 용도
루트 모듈에서 사용자가 확인하고자 하는 특정 속성 출력
자식 모듈의 특정 값을 정의하고 루트 모듈에서 결과를 참조
서로 다른 루트 모듈의 결과를 원격으로 읽기 위한 접근 요소
정의시 사용 가능 메타 인수
description : 출력 값 설명
sensitive : 민감한 출력 값임을 알리고 테라폼의 출력문에서 값 노출을 제한
depends_on : value에 담길 값이 특정 구성에 종속성이 있는 경우 생성되는 순서를 임의로 조정
precondition : 출력 전에 지정된 조건을 검증
예시
resource "local_file" "abc" {
content = "abc123"
filename = "${path.module}/abc.txt"
}
output "file_id" {
value = local_file.abc.id
}
output "file_abspath" {
# abspath : 파일 시스템 경로를 포함하는 문자열을 가져와 절대 경로로 변환하는 함수
value = abspath(local_file.abc.filename)
}
실행
# plan 실행 시, 이미 정해진 속성은 출력을 예측하지만
# file_id는 예측할수 없으므로 known after apply로 표시
terraform init && terraform plan
...
Changes to Outputs:
+ file_abspath = "/Users/gasida/Downloads/workspaces/3.8/abc.txt"
+ file_id = (known after apply)
#
terraform apply -auto-approve
...
Outputs:
file_abspath = "/Users/gasida/Downloads/workspaces/3.8/abc.txt"
file_id = "6367c48dd193d56ea7b0baad25b19455e529f5ee"
#
terraform state list
terraform output
3.9 반복문
list 형태의 값 목록이나 Key-Value 형태의 문자열 집합인 데이터가 있는 경우 동일한 내용에 대해 테라폼 구성 정의를 반복적으로 하지 않고 관리할 수 있다.
인프라를 더 이상 소유하지 않고 상품화된 인프라와 데이터 센터를 사용하는 단계 → 기본적으로 클라우드 리소스를 원격 관리 가능
빠른 인프라 시작 구성 가능, 뛰어난 확장성
단점
클라우드 제공자마다 서로 다른 API
멀티 클라우드 자동화 위해서는 ? → 개별적인 작업이 추가로 필요
Container
물리적머신 → VM→OS를 가상한 환경 제공
최근 데브 옵스 흐름 → 더 빠른 성장
k8s같은 오케스트레이션 사용 → 특정 서버가 아닌 적절한 리소스의 어떤 서버에 배포 → 리소스 활용율 ↑, 이전보다 더 자동화
가용한 모든 리소스 확장 가능
매우 빠른 배포 전략 도입
역설적인 단점 : 자동화의 역설
기존 : 물리적 하드웨어가 VM으로 가상화 → 이를 제어하기 위한 SW 관리 작업이 추가 됨
컨테이너도 관리와 배포를 위한 제어 시스템 구축 → 모니터링 노력이 상대적 커짐 → 자동화의 역설
가장 최신 기술 → 컨테이너 개발/운영 전문 인력이 부족
_1.2 프로세스로서의 자동화
자동화: 각 프로세스 작업을 통합하고 재활용성을 높이는 것이 중요하다
이전 자동화 방향성 : “기술 주도형 접근”
강력한 엔지니어적 협조
빅뱅방식 적용
개발 기간을 정하고
모든 시스템을 일괄적으로
구축 또는 업그레이드 하는 개발 방식
느리고 매뉴얼화된 절차적단계를 거쳐 프로세스 진행
단계별로 파편화된 자동화 → 특정 환경에서만 동작
따라서 내부에서 구축된 리소스 자동화에 적합
새로운 자동화 필요 : CI/CD
고정적이지 않고 추상화된 리소스 → 기존 자동화 재적용 어려움
동적 인프라(like 클라우드)+ 다른 플랫폼 기술 융합 자동화 → 프로세스적인 접근법 필요
작은 규모로 독립성을 유지 관리 → 주기적인 변경과 적용 방식 지향 → 빠른 시장 적응과 장애 극복 능력 획득 필요
코드 표현 방식에 기반한 자동화 설계 → 개별 서비스를 릴리즈 하기 위한 반복 작업 효율화
자동화의 역설 어게인
기존 하드웨어 기반에 비해 시간과 인력 소모 → 자동화 할수 있는 API인터페이스 제공
자동화(가상화↑, 컨테이너화) → 일반적으로 업무량이 줄고 더 나은 워라밸이 가능해야 한다
자동화의 역설 → 무수히 많은 반복과 검증 작업 필요 → 이전보다 더 많은 시간과 노력을 요구하기도 한다
더 아이러니 한 것
인프라 관리, 운영을 위한 단계 방식이 어느 것 하나 없어지지 않음
VM, 베어메탈 같은 서버 환경이 현재도 존재
기존 서버 환경보다 더 작은 Edge, IOT 인프라도 관리대상 추가
1.3 IaC의 이해
코드로 인프라를 관리 한다는 것
“자유롭게 변경”하고
“환경을 이해”하고
“반복적으로 동일한 상태”를 만들 수 있다
이에 대한 명세를 별도의 문서로 정리하지 않아도 인프라가 명확하게 정의되어 남게 된다
좋은 코드의 특징을 먼저 살펴보면
잘 작동함
관리가 쉬움
읽기 쉬움
변경이 쉬움
모듈화 됨
간결하고 명확함
테스트 가능함
효율적임
보기 좋음 -우아함
좋은 코드의 특징과 IaC의 관계
인프라도 좋은 코드처럼 관리가 가능
자동화를 위해 → 문서화
인프라 종속성 분석해서 관리
인프라 자원 있을때마다 변경
결과물이나 결과물 만드는 도구를 관리
인프라를 위한 좋은 코드 : 연습이 필요하다
> IaC (Infrastructure as Code)는 코드로 인프라를 관리하는 것으로,
> 좋은 코드의 특징과 비슷합니다.
> 인프라도 코드처럼 잘 작동하고, 관리가 쉽고, 읽기 쉽고, 변경이 쉽고,
> 모듈화되며, 간결하고 명확하며, 테스트 가능하고, 효율적이며, 우아합니다.
> IaC는 이러한 좋은 코드의 특징을 활용하여 인프라를 자동화하고,
> 문서화하고, 인프라 종속성을 분석하여 관리하며, 인프라 자원이 있을 때마다
> 변경하며, 결과물이나 결과물을 만드는 도구를 관리합니다.
> 이러한 과정 없이, 좋은 코드가 좋은 인프라 자동화로 이어지도록 만들어줍니다.
IaC 장점
속도와 효율
버전 관리
협업
재사용성
기술의 자산화
IaC 우려 측면
코드 문법 학습 - 새로운 도구를 위한 학습 필요
파이프라인 통합 - 기존 워크플로에 자동화를 위한 수고가 추가로 필요
대상 인프라 이해 필요 - 관리 대상이 되는 인프라의 지식이 필요
1.4 테라폼의 특성
테라폼 : 하시코프사
3가지 철학 - 워크플로에 집중, IaC, 실용주의
workflow -Workflows, not technologies
solution - 기술, 기능 구현을 위해 만들어진다
어떤 기능 하나가 모든 것을 해결해주지 않음
테라폼 : 개발자/관리자가 일하는 방식과 유사한 workflow를 만들기 위한 도구로 설계
Ubuntu 에 apache(httpd) 를 설치하고 index.html 생성(닉네임 출력)하는 userdata 를 작성해서 설정 배포 후 웹 접속 - 해당 테라폼 코드(파일)를 작성
provider "aws" {
region = "ap-northeast-2"
}
resource "aws_instance" "example" {
ami = "ami-0c9c942bd7bf113a2"
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.instance.id]
user_data = <<-EOF
#!/bin/bash
apt-get update
apt-get install -y apache2
service apache2 start
echo "My Nickname : rkaehdaos" > /var/www/html/index.html
EOF
tags = {
Name = "Single-WebSrv"
}
}
resource "aws_security_group" "instance" {
name = var.security_group_name
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
variable "security_group_name" {
description = "The name of the security group"
type = string
default = "terraform-example-instance"
}
output "public_ip" {
value = aws_instance.example.public_ip
description = "The public IP of the Instance"
}
첫 주 스터디를 하기 전에 예습을 했어야 했는데...
정말 내가 이상한지 모르겠는데.. IaC는 그냥 프로그램하고는 다르다.. 분명히 스터디 하고 영상 다시 보기 할 떄는 맞아 맞아.. 그거지..했는데.. 막상 도전 과제 하나 하려니.. 정말 실습에서 아주 조금 비튼 건데.. 지금 몇 시간을 날린건지..새벽 2시가 되서야.. ㅠ 과제는 과제로 치고.. 진짜로 빡집중하자 진짜로.