본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
https://bit.ly/4hTSJNB
I. 학습 인증샷 4장 이상 포함
1. 공부시작: 날짜, 시각 다 나오도록

2. 공부 종료: 날짜 시각 다 나오도록

3. 1개 클립 수강 (강의장 목록 캡쳐, 수강화면이 보이지 않도록) 1장

4. 학습 인증샷 1장(필기 촬영이나 작업물 촬영)

II. 학습 후기 700자 이상 (공백 제외)
카프카의 로그 관리에 대한 심화 강의이다.
요약
로그 정리 정책 (Log Cleanup Policy)
- Log는 Consume되어도 지우지 않음
- 많은 Consumer들이 서로 다른 시간에 Log 데이터를 Consume 할 수 있기 때문에
- Broker 혹은 Topic 단위로 Cleanup 정책을 설정함
- log.cleanup.policy 파라미터
- delete
- compact
- delete,compact: 2개 동시 사용
- 현재 Active Segment의 Log는 cleanup 대상이 아님!
삭제 정리 정책 (Delete Cleanup Policy) : Log Segment 삭제 정책
- Log Cleaner Thread가 Segment File을 삭제
- log.cleanup.policy 파라미터
- delete
- log.retention.ms : log 보관 주기 (기본값 : 7 일)
- log.retention.check.interval.ms : log segment를 체크하는 주기 (기본값 : 5 분)
- segment 파일에 저장된 가장 최신의 메시지가 log.retention.ms 보다 오래된 segment 를 삭제
Topic 메시지 모두 삭제 하는 방법 : retension.ms 활용 : 운영환경에서는 권장하지 않음
- Producer와 Consumer를 모두 shutdown
- 명령어를 사용하여 해당 Topic의 retention.ms를 0으로 셋
- Cleanup Thread 가 동작할 동안 대기 (기본값 5분 마다 동작)
- 메시지 삭제 확인 후, 원래 설정으로 원복
주의) 절대 Log File을 직접 삭제하면 안된다. 카프카 깨짐
압축 정리 정책 (Compact Cleanup Policy)
- 주어진 키의 최신 값만 유지하는 정책
- 파티션별로 특정 키의 최신 값만 유지하며 압축
- 시스템 오류 후 상태 복원에 유용
- 동일한 Key를 가진 메시지가 다른 Partition에 있는 경우
- 동일한 Key를 가진 여러 메시지가 여전히 있을 수 있음
- 중복 제거용 기술이 아님
로그 압축 (Log Compaction)
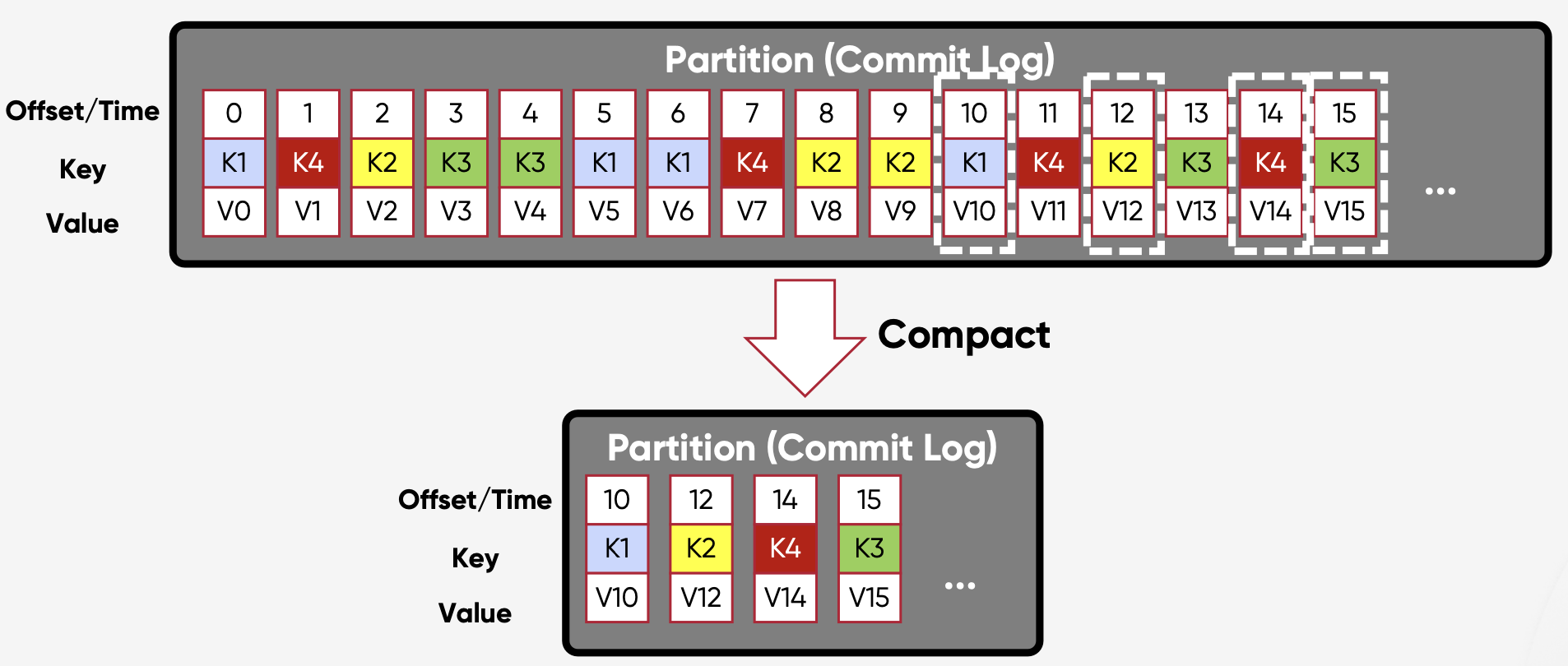
- 키가 있는 메시지에 대해서만 작동
- 압축이 없는 경우 Consumer가 각 키의 최신상태에 도달하기 위해서는 항상 전체 Log를 읽어야 한다.
- 로그 압축을 사용하면 오래된 데이터를 읽지 않아 최종 상태에 빠르게 도달 가능
Tombstone 메시지: Log Compaction시 특정 Key 데이터 삭제
- 목적
- 논리적 삭제 표시
- 키는 있지만 값이 null인 메시지로 구성
- 특정 키에 대한 레코드의 논리적 삭제를 나타낸다.
- 로그 압축 지원
- 압축된 토픽에서 이전 값들을 실제로 삭제하는데 사용
- 로그 압축시 특정 키의 데이터를 삭제하는 매커니즘 제공
- Compaction 사용시에 Key로 K를 가지는 메시지를 지우려면
- 동일한 Key(K)에 null value를 가지는 메시지를 Topic으로 보내면 됨
- 논리적 삭제 표시
- Consumer는 해당 메시지가 지워지기 전에(기본 1 day), 해당\메시지를 consume할 수 있음
- 메시지를 지우기 전 보관 기간(기본 1 day)은 log.cleaner.delete.retention.ms 로 조정
log라 함은 tomcat의 log, rabbitmq의 log로.. 에러만 처리하고 압축 보관 및 지워야하는 대상으로 여기게 된다.
하지만 절대 직접 지우면 안된다는 말에 ..순간 다시 개념이 떠올랐다.
카프카의 로그는 단순한 에러메시지나 시스템 기록이 아닌 실제로 메시지 자체를 의미한다는 것을...
로그가 소비되어도 바로 삭제되지 않는다는 것!
여러 소비자가 서로 다른 시간에 로그 데이터를 소비할 수 있기 때문이라고 한다.
이런 특성 때문에 카프카가 다양한 시스템에서 유연하게 사용될 수 있다는 걸 깨달았다.
하지만 그러기 때문에 더더욱 삭제 정리 정책과 압축 정리가 중요해 보인다.
삭제 정책은 단순히 오래된 로그를 지우는 반면, 압축 정책은 각 키의 최신 값만 유지한다는 점이 인상적이다.
특히 압축 정책이 시스템 오류 후 상태를 복원하는 데 유용하다는 설명을 들으면서,
실제 업무에서 어떻게 활용될 수 있을지 상상해보게 되었다. 다만 실제 운영 이슈에서 버그 재현시에는
전체 메시지가 전부 있어야 완전하게 버그 재현이 가능하지 않을까 싶은데..
로그 압축의 동작 원리를 설명하는 부분에서는 조금 햇갈렸다..
Tail과 Head 영역, Cleaner Point 등의 개념이 처음에는 복잡해 보였지만,
강사님이 자세히 설명해주고 그림을 자세히 살펴보니 조금씩 이해가 되기 시작했다.
역시 만족스럽다.
Tombstone 메시지라는 개념도 처음 들어보는 개념이다.
압축 정책을 사용할 때 특정 키의 데이터를 삭제하는 방법이라고 한다..
실제로 null 값을 가진 메시지를 보내서 데이터를 삭제한다는 아이디어는 그 어디서도 볼 수 없는 부분이다.
혹시 몰라서 인터넷을 뒤져보니까.강의처럼 로그 압축 시나리오에서 압축된 토픽에서 오래된 레코드 제거하고 최신상태 유지할때 사용되는
부분이 있었다. 하지만 더 많은 부분은 분산시스템 동기화나 상태기반 어플리케이션의 특정 키 존재 관리에서 사용하는 등 쓰임새가 다양했다. 해당 부분을 설명안하는 것은 아직 필요가 없으니까 안한 것이었다.. 괜히 검색해서.. 더 머리가 복잡해졌다.
실무에서 사용가능한 성능튜닝에 사용할 값들이 (위 필기에서 나온 것처럼) 나오긴 했다. 하지만
어떤 좀더 사용사례들에 대한 여러 값들과 정책 설정 규칙을 알려주면 좋겠다.
그리고 아무래도 위의 내용은 나중 실습 때 실제로 적용해보고 내용을 봐야 내 것이 되지 않을까 싶다.
'패캠챌린지 > Kafka EcoSystem - 진행중' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 18일차 : 한번에 끝내는 KafkaEcosystem 강의 후기 (0) | 2025.03.22 |
|---|---|
| 패스트캠퍼스 환급챌린지 17일차 : 한번에 끝내는 KafkaEcosystem 강의 후기 (0) | 2025.03.21 |
| 패스트캠퍼스 환급챌린지 16일차 : 한번에 끝내는 KafkaEcosystem 강의 후기 (0) | 2025.03.20 |
| 패스트캠퍼스 환급챌린지 15일차 : 한번에 끝내는 KafkaEcosystem 강의 후기 (0) | 2025.03.19 |
| 패스트캠퍼스 환급챌린지 14일차 : 한번에 끝내는 KafkaEcosystem 강의 후기 (0) | 2025.03.18 |

감동맨
rkaehdaos의 블로그